I work a ton with data. It's fun. But sometimes I need data that's just not readily available. Sure, maybe it exists on a website somewhere, but who has the time to sit and download data over and over. I started developing webscraping scripts a few months back when I realized I could collect all the data I needed with minimal manual work. As I've learned more and more ways to download increasingly complicated data, I've also learned how to make the process much faster.
One of the best methods I've discovered for quick and easy scraping is using Pandas DataFrames. I used to write code that used regex to loop through HTML and build tables, but that process can take forever. In this blog I'll show you how I scraped the Spotify Top 200 Charts in order to give you a quick run through of how you can use Pandas to speed up your webscraping.
I'll be walking through a script I wrote while working on a project where a music streaming company was suing a musician. In order to calculate damages we wanted to gather data on the artists playcounts so we could better quantify the value of being on the service.
You're only going to need three packages: Pandas, Requests, and Datetime. In case you're not familiar, Requests is really useful anytime you need to use Python to request information from a website. (See here for a useful guide).
import pandas as pd
import requests
from datetime import timedelta
pd.set_option('display.max_rows', 20)
We can start by opening the link to the spotify charts for October 13, 2019 with the Requests package and getting an idea of what the HTML code looks like. Once you've opened the link, you can use the responses text attribute to view the HTML.
LINK = 'https://spotifycharts.com/regional/us/daily/2019-10-13'
response = requests.get(LINK)
response.text[0:2000]
The HTML alone isn't really that useful, except maybe to show that we're able to download the text. What we want to be able to do is download the table embedded in the HTML that has artist, song, and play count information that we can see below. You can check the HTML code on the website to confirm existence of the table tag. Pandas will look for that tag and will pull the HTML code underneath it into table form.
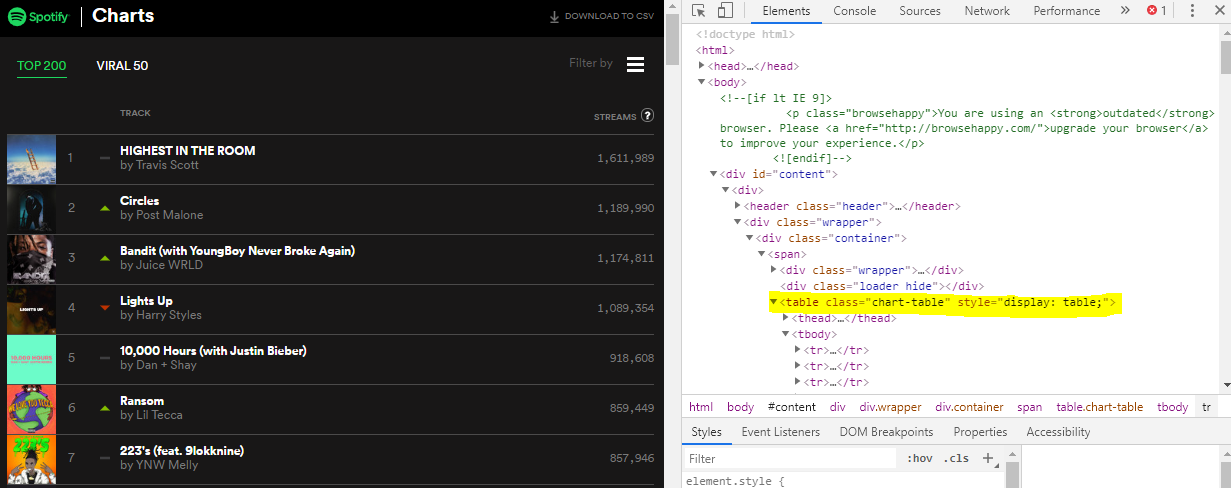
Luckily, now that we have the HTML, it's really easy to pull this into a DataFrame. All we need to do is run the HTML text through the Pandas read_html function and we will have a table with all the information we need. It's important to convert the response output (or whichever program you're using to scrape the webpage) to readable HTML first.
df = pd.read_html(response.text)
df
Note that the output is actually in list form. Often it's the case that Pandas will read in more than one table from the HTML code so you need to think about which table you want and then how to pull that table from the list and/or how to save each table to individual variables. Here it's easy, we can just take the 0th value from the list.
df = df[0]
Now that we have the data in a DataFrame we need to clean it up. What I want to do is have track title and artist in seperate columns, drop empty columns, and properly name all remaining columns. We should also add a date column so when we look at the table again we know what date it's for. Fortunately, there's not much more cleaning required than that.
df.dropna(how='all', inplace=True, axis=1)
trackname_artist = df['Track'].str.split(' by ', expand = True)
df['Song'] = trackname_artist[0]
df['Artist'] = trackname_artist[1]
df.rename(columns ={'Unnamed: 1': 'Position',
'Track': 'Full Name'}, inplace = True)
df['Date'] = '2019-10-13'
df.head()
Putting it all together:¶
Having one day of data may not be enough, and in the case of my project, we needed 40 days worth. The easiest way to get 40 days of data (which requires scraping 40 different webpages) is to make a flexible function and loop through it, which I've done below. If you do want to scrape the top 200, this function will work well. You just need to specify the date you need the data and which region you want the data for.
def get_daily_chart_data(date, region ='us'):
"""
For a given region and given date, pulls that days top 200 songs
and number of plays
date: date in "yyyy-mm-dd" format
region: any that shows up in link when changed here: https://spotifycharts.com/regional
"""
LINK = 'https://spotifycharts.com/regional/%s/daily/%s' %(region, date)
response = requests.get(LINK)
response = response.text
table_data = pd.read_html(response)[0]
table_data.dropna(how='all', inplace=True, axis=1)
trackname_artist = table_data['Track'].str.split(' by ', expand = True)
table_data['Song'] = trackname_artist[0]
table_data['Artist'] = trackname_artist[1]
table_data.rename(columns ={'Unnamed: 1': 'position',
'Track': 'Full Track Name'}, inplace = True)
table_data['Date'] = date
return table_data
Finally, we can define a few variables and run the loop. Looping through dates can be a bit weird because you should be starting with datetime formatted dates so you can easily increase the date value but then you need to convert back to string so you can use the date in the function.
START_DATE = '2018-10-01'
START_DATE = pd.to_datetime(START_DATE)
NUMBER_OF_DAYS = 10
if __name__ == "__main__":
songs = pd.DataFrame()
for i in range(0, NUMBER_OF_DAYS):
date = START_DATE.date().strftime('%Y-%m-%d')
temp = get_daily_chart_data(date)
songs = pd.concat([songs, temp])
START_DATE = START_DATE + timedelta(days=1)
songs.reset_index(drop=True, inplace=True)
We now have 10 days of Spotify top 200 data that we can play around with. For example, we could look at which artist had the most number of singles during that time period.
(songs.groupby(by= ['Artist', 'Song']).size().reset_index()
.groupby(by='Artist')['Song'].count().reset_index()
.sort_values('Song', ascending = False)).head(10)
The top artist during that time period was Lil Wayne with 23 (!!!) singles in the top 200 over the selected 10 days. This isn't a huge surprise since Lil Wayne released his album Tha Carter V at the end of September. What is a surprise is how the top 10 artists with the most different songs on the top 200 are hip-hop(ish). The rise of hip-hop is definitely an area I've been interested in and will explore more in the future.
We can also see what songs were the most streamed in this time period.
songs.groupby(by ='Song')['Streams'].sum().reset_index().sort_values(by = 'Streams', ascending=False).head(10)
If there's one thing to take away from this it's that the top 10 most streamed songs during this time period were BANGERS.
We could even make a quick chart to see how many streams the top 200 songs received on any given day. October 5th is a Friday if you're wondering why there's a big spike on that day.
chart = songs.groupby(by ='Date')['Streams'].sum().reset_index().plot.bar(x = 'Date', y='Streams')

Hopefully by now you have a good idea of how you can get started with webscraping. It's much less daunting than I initially thought and hopefully you feel the same way.
Since learning webscraping I've been tasked with scraping websites that really don't want me to scrape. These websites use all sorts of tricks to try and stop me, but with a few lines of code, I've learned to trick these website. I've also learned a lot about how to amp up webscraping capabilities by using browser automation which will be a topic for next time.
Comments !